LLM
A Large Language Model (LLM) is a type of artificial intelligence model trained on vast amounts of text data to understand, generate, and manipulate natural language. Built on the Transformer architecture, LLMs use billions of parameters to recognize semantic patterns and reasoning relationships.
Frequently Asked Questions
What does the "Large" in Large Language Model refer to?▼
It refers to both the massive size of the training datasets (often terabytes of text) and the high parameter count of the model (ranging from billions to trillions of weights).
How do LLMs generate responses?▼
They generate text token-by-token. Given a prompt context, the model calculates the probability distribution for the next token and samples from it, recursively appending the output to generate sentences.
Quick Facts
- CategoryFoundational AI
- Key ApplicationConversational chatbots, text summarization, automated code generation, and semantic search translation.
Coverage Trend12 Weeks
Related AI Terms
LLM Media Coverage & Intelligence
A startup claims it broke through a bottleneck that's holding back LLMs
Miami-based AI startup Subquadratic came out of stealth mode last month with a huge claim. It announced that it had solved a mathematical bottleneck that had be
Emergent Alignment
Can Large Language Models (LLMs) discern when their own outputs are misaligned with human ethics? And can they self-correct? We endow an LLM with a conscience s
Which Pairs to Compare for LLM Post-Training?
Preference-based post-training has become a central paradigm for aligning language models. A common data-collection strategy is to generate a small set of compl
Deontic Policies for Runtime Governance of Agentic AI Systems
Autonomous agentic AI systems driven by Large Language Models (LLMs) introduce a new class of security, privacy, and compliance challenges: an agent that can in
Diffusion Language Models: An Experimental Analysis
Large Language Models (LLMs) have revolutionized language modeling through autoregressive generation, enabling strong performance across a wide range of tasks.
Hidden Anchors in Multi-Agent LLM Deliberation
Multi-agent LLM deliberation, where agents exchange and revise answers over several rounds, is increasingly used to improve reasoning and accuracy, yet how and
DeXposure-Claw: An Agentic System for DeFi Risk Supervision
Decentralized finance exposes supervisors to fast-moving, networked credit risks. General-purpose LLM agents fit this setting poorly: they over-read weak eviden
LLM Doesn't Know What It Doesn't Know: Detecting Epistemic Blind Spots via Cross-Model Attribution Divergence on Clinical Tabular Data
Large language models (LLMs) are increasingly applied to structured clinical data, yet whether they can recognize the limits of their own knowledge on such task
Uncertainty Decomposition for Clarification Seeking in LLM Agents
Recent position papers argue that the classical aleatoric/epistemic uncertainty framework is insufficient for interactive large language model (LLM) agents and
Analyzing the Narration Gap in LLM-Solver Loops
Formal tools such as SAT and SMT solvers are increasingly embedded in language model reasoning pipelines when a safety or security critical question can be form
Copilot searched your mailbox. LiteLLM handed out admin keys. Run this 5-check audit before your stack is next
Two AI tools broke in the same way in the same two weeks, and four research teams proved it. The pattern underneath every disclosure is one sentence: enterprise
Decoupling Search from Reasoning: A Vendor-Agnostic Grounding Architecture for LLM Agents
Production LLM agents increasingly depend on real-time search, yet native search grounding bundles retrieval policy, provider choice, evidence injection, cost,
SciRisk-Bench: A Risk-Dimension-Aware Benchmark for AI4Science Safety
Large language models (LLMs) are increasingly embedded in AI for Science (AI4Science) workflows, from scientific question answering and literature analysis to l
ProfiLLM: Utility-Aligned Agentic User Profiling for Industrial Ride-Hailing Dispatch
Bringing Large Language Models (LLMs) into industrial ride-hailing dispatch as semantic feature extractors over platform-scale behavioral logs is a compelling b
World model maker Odyssey nabs $1.45B valuation backed by Amazon and other big names
World models are the next big thing in AI beyond LLMs and, with this round, Odyssey has cemented itself as one of the startups to watch.
Collecting robot training data is dirty, unglamorous work. Some AI labs are already paying XDOF to do it.
If physical AI is going to match the accomplishments of LLMs, there's a data problem that needs to be solved.
Incumbent Advantage: Brand Bias and Cognitive Manipulation Dynamics in LLM Recommendation Systems
Large language models (LLMs) are becoming a major way for consumers to find products, but we do not yet understand how brands compete in this new channel. We st
Quantifying Consistency in LLM Logical Reasoning via Structural Uncertainty
Large language models can arrive at the same answer through reasoning paths that are unstable, contradictory, or difficult to rank consistently -- a failure mod
Z.ai's open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost
Today, Chinese AI startup Z.ai (formerly Zhipu AI) announced the immediate release of GLM-5.2 , a 753-billion parameter open-weights large language model (LLM)
MLPerf Training v6.0: Lambda delivers fastest LLM training on NVIDIA GB300 NVL72 and fastest MoE training on NVIDIA HGX B200
Lambda's GB300 NVL72 Llama 3.1 8B MLPerf Training v6.0 submission improved performance by 18.7% over Lambda's previous result, achieving the fastest convergence on this round's workload on GB300 NVL72. In addition, Lambda achieved the fastest result among single-node HGX B200 submissions for GPT-OSS
Critical Copilot vulnerability allowed hackers to steal 2FA code from users
SearchLeak exploit shows why the industry's approach to LLM security fails over and over.
Rewriting Your Pitch: SaaS Isn't Dead, But The Playbook For Founders Is Changing
Because AI and LLMs are reshaping the traditional SaaS model, founders are forced to focus less on software alone and more on delivering measurable business out
Google researchers introduce 'faithful uncertainty,' allowing LLMs to offer best guesses instead of hallucinations
Large language models continue to struggle with hallucinations, presenting a major roadblock for real-world enterprise applications. Reducing these errors is a
Building Supercharger: How Rocket Close optimized title operations with agentic AI
In this post, we explore how Rocket Close built a solution using Strands Agents, large language models (LLMs), Amazon Bedrock, Amazon Bedrock Knowledge Bases, a
Context compression finally works in production: new research cuts LLM input 16x without the accuracy hit
Context windows are becoming a computational bottleneck. The longer an agent runs, the more tokens accumulate from retrieved documents, reasoning traces and con
Making secret scanning more trustworthy: Reducing false positives at scale
Alerts are more trustworthy and actionable when noise is reduced. See how we improved the verification step with context-aware LLM reasoning. The post Making se
Mind the Perspective: Let's Reason Recursively for Theory of Mind
Theory of Mind (ToM) reasoning requires inferring agents' beliefs from partial and asymmetric observations, which remains an open challenge for LLMs. Existing p
Researchers say they trained a foundation model from scratch for about $1,500
Training a foundation LLM from scratch costs millions and requires internet-scale data - which is why most enterprises don't bother. Sapient thinks it has a che
Less Context, Better Agents: Efficient Context Engineering for Long-Horizon Tool-Using LLM Agents
Large language models deployed as autonomous agents for enterprise workflows face a key challenge: verbose tool responses from enterprise systems can cause cont
Context windows in AI: why every token is a budget decision
Some of today's most capable LLMs now support very large context windows. That doesn't mean you should fill them. Context windows have grown fast, but the underlying cost and quality tradeoffs haven't gone away. They've just gotten easier to ignore. ...
How Far Did They Go? The Persuasive Tactics of Covert LLM Agents in a Discontinued Field Experiment
This study analyzes a publicly released dataset from a discontinued field experiment on Reddit's r/ChangeMyView.
Minimizing the Hidden Cost of Scales: Graph-Guided Ultra-Low-Bit Quantization for Large Language Models
Post-training quantization (PTQ) is critical for the efficient deployment of large language models (LLMs). Recen
Mutation Without Variation: Convergence Dynamics in LLM-Driven Program Evolution
When an LLM repeatedly mutates a program, does it explore new forms or circle back to the same ones? We study th
StepPRM-RTL: Stepwise Process-Reward Guided LLM Fine-Tuning for Enhanced RTL Synthesis
Automatic generation of RTL code for digital hardware designs remains challenging due to long-horizon reasoning,
Exploring Cross-Scenario Generality of Agentic Memory Systems: Diagnostics and a Strong Baseline
LLM agents accumulate histories that outgrow their context windows, motivating a growing literature on memory sy
AgentJet: A Flexible Swarm Training Framework for Agentic Reinforcement Learning
We present AgentJet, a distributed swarm training framework for large language model (LLM) agent reinforcement l
The Saturation Trap and the Subjectivity of Intervention Timing: Why Affect-Based Triggers and LLM Judges Fail to Time Interventions on Autonomous Agents
As autonomous AI agents move from conversational systems to long-horizon software execution, runtime safety laye
Airbnb's Brian Chesky plans to launch a new AI lab
The Airbnb CEO said last year it hasn't struck an LLM partnership because existing products weren't quite ready.
These LLMs are the best at resisting Russian propaganda
Estonian government benchmark shows how dozens of models combat Russia's "strategic narratives."
Alibaba's Qwen3.7-Plus supports text, video and imagery inputs at low cost of $0.4/$1.6 per 1M token - but it's proprietary
Alibaba this week released Qwen3.7-Plus , the latest AI large language model (LLM) in its globally beloved and increasingly expansive Qwen family, boasting more
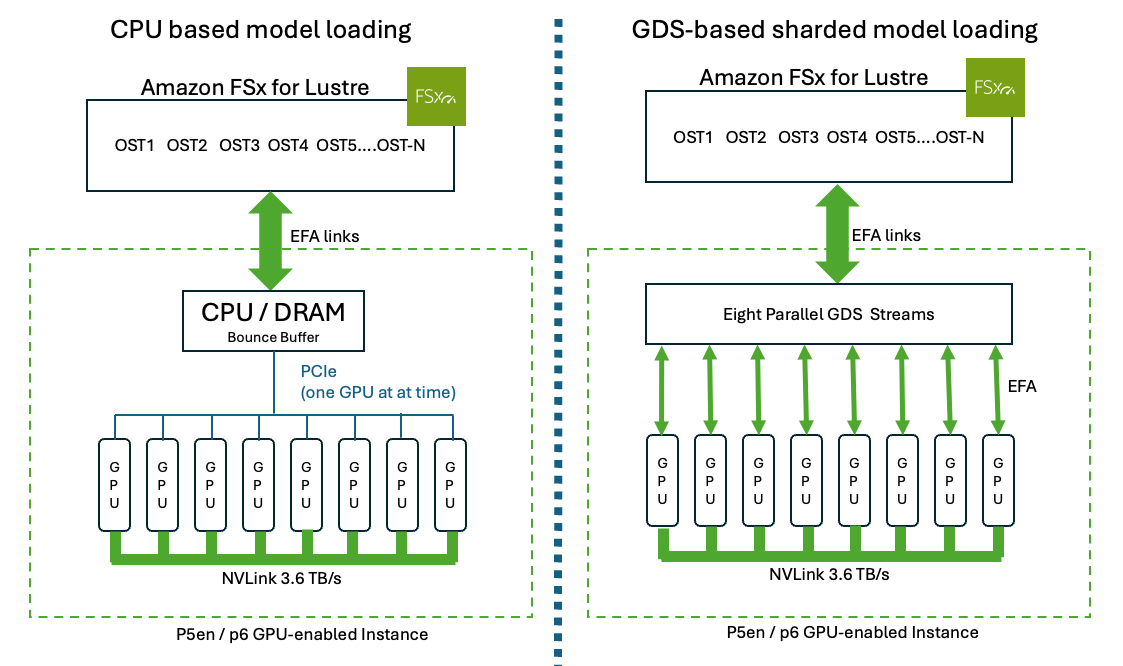
Accelerate LLM model loading and increase context windows with GPUDirect on Amazon FSx for Lustre and TurboQuant
If you're iterating on deploying large language models (LLMs) on AWS GPU instances, you've probably noticed the larger the model to be loaded into GPU High Band