Inference
Inference is the process of using a trained AI model to make predictions or generate text based on new inputs. During inference, data flows forward through the neural network to produce an output, without modifying the model's weights.
Frequently Asked Questions
How does inference differ from training?▼
Training calculates errors and updates the model's weights. Inference just uses the already-calculated weights to process new data.
Why is inference speed important?▼
Low latency inference is critical for interactive user experiences (e.g. conversational voice agents).
Quick Facts
- CategoryModel Operations
- Key ApplicationReal-time chat responses, API query execution, and mobile-device AI features
Coverage Trend12 Weeks
Related AI Terms
Inference Media Coverage & Intelligence
Monitor and debug generative AI inference with SageMaker detailed metrics and Insights dashboard on CloudWatch
Amazon SageMaker AI provides fully managed real-time inference hosting for machine learning models. You deploy a model to a SageMaker endpoint backed by one or
Context is becoming the missing layer in enterprise AI
The enterprise AI market is entering a new phase. For the past several years, the focus has been on larger models, faster inference and broader deployment of generative AI capabilities. Yet despite growing investment, many organizations continue to struggle with governance, accuracy, operational sca
AI inference startup Baseten reportedly raising $1.5B months after its last mega-round
Startup Baseten is reportedly close to finalizing a $1.5 billion round at a $13 billion as the "inference gold rush" marches on.
AI inference provider Baseten reportedly raising $1.5B in funding
Baseten Inc., a startup with a platform for running artificial intelligence inference workloads, is raising $1.5 billion in funding. The Wall Street Journal reported today that Altimeter Capital, Conviction, Spark Capital, Sands Capital and Wellington Management are co-leading the deal. It's unclear
Kimi K2.7 Code Now Available on Serverless Inference with Leading Benchmark Price-Performance
CoreWeave Inference achieves the highest output speed for the newly-launched Kimi K2.7 Code and ranks in the most attractive price-performance quadrant.
Production AI Runs on Inference. Are You Ready for It?
Production AI depends on inference. Learn how to evaluate reliability, cost, and control and choose the right inference deployment for every workload.
Choosing the Right NVIDIA Platform for Running Inference on CoreWeave
Explore the ideal NVIDIA GPUs for running inference on CoreWeave-optimize latency, reduce token cost, and match your model to the ideal GPU for real-time performance.
Why Inference Latency and Availability Drift in Production
Latency drift and gradual availability failures are the defining production inference challenge. This blog describes where drift originates and what to measure before it reaches your users.
CoreWeave Closes the Loop Between Training and Inference
CoreWeave unifies training and inference so AI agents can learn in production, improve autonomously, and evolve into productive coworkers with serverless RL and observability.
Lights. Camera. Inference. CoreWeave Powers the Next Act of AI Creation.
CoreWeave expands Conductor into AI workflows, enabling faster, secure training and inference for creative teams across sports, entertainment, and gaming.
Amazon SageMaker AI Async Inference now supports inline request payloads
Today, we're announcing inline payload support for Amazon SageMaker AI Async Inference. Customers can now send inference payloads directly in the request body o
Introducing container caching in Amazon SageMaker AI for faster model scaling
Today, we're excited to announce container image caching for Amazon SageMaker AI inference, the next major advancement in our faster scaling optimization journe

Exclusive: Mindbeam touts dramatic performance improvements in CPU-based AI inference
Two-year-old startup Mindbeam AI Inc. today released an open-source artificial intelligence inference framework designed to make large language models run more efficiently on standard consumer processors, a move the company says could reduce reliance on expensive graphics processing units for some A
Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
Compact language models (LMs) reduce cost, latency, and deployment risk for tool agents. Yet MCP-style tool use requires more than isolated function calling: an
Extract Data with On-demand and Batch Pipelines Dynamically
This post demonstrates an intelligent document processing pipeline that consists of both on-demand inference and batch inference options on Amazon Bedrock to en

QumulusAI and the shift from GPU scarcity to GPU efficiency
Neocloud provider QumulusAI announced today that it has secured more than $124 million in customer subscriptions for three-year terms with Hyperbolic and another leading artificial intelligence inference platform. These agreements cover deployments totaling 1,280 Nvidia Corp. Blackwell GPUs, deliver

Inference Is Your Product's Reliability Layer
Learn how CoreWeave helps AI teams manage latency, cost, and control before production issues reach users.

NVIDIA Confidential Computing to Help Expand Apple's Private Cloud Compute
NVIDIA GPUs with Confidential Computing are now used for confidential inference in Apple's Private Cloud Compute (PCC), as it expands beyond Apple's data center
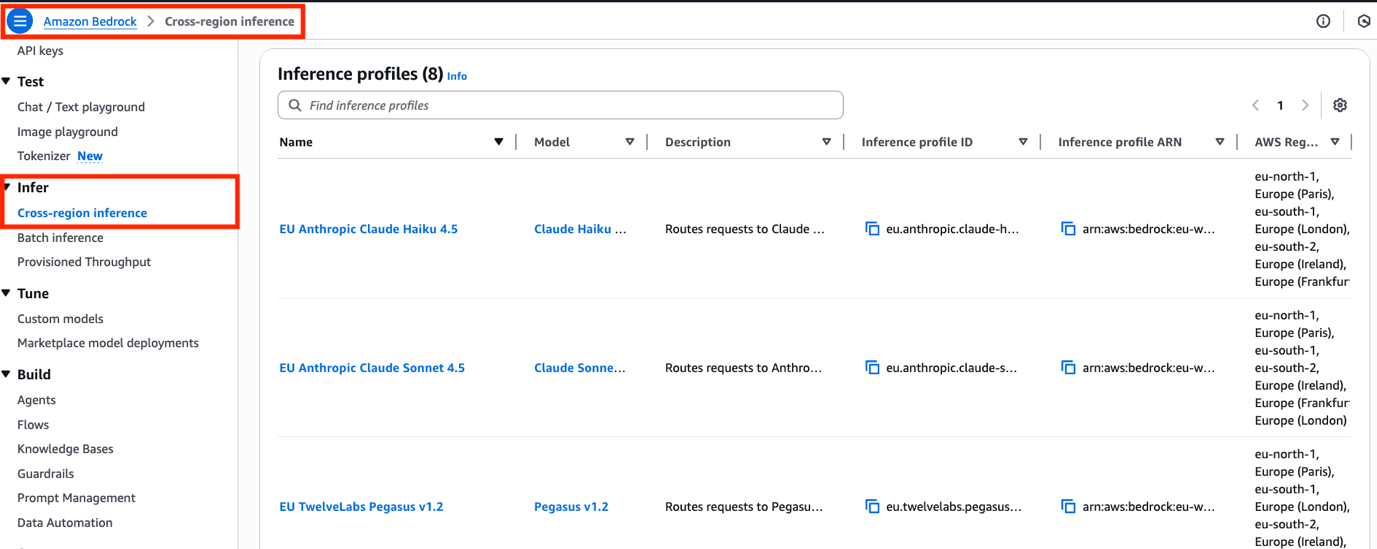
Unlocking AI flexibility in Europe: A guide to cross-region inference for EU data processing and model access
With access to the latest generative AI models and high-performance accelerated compute in high global demand, AWS customers need tools to take advantage of mod
GITCO: Gated Inference-Time Context Optimization in TSFMs
Patch-based Time Series Foundation Models (TSFMs) suffer from context poisoning: structurally anomalous patches capture disproportionate attention and silently
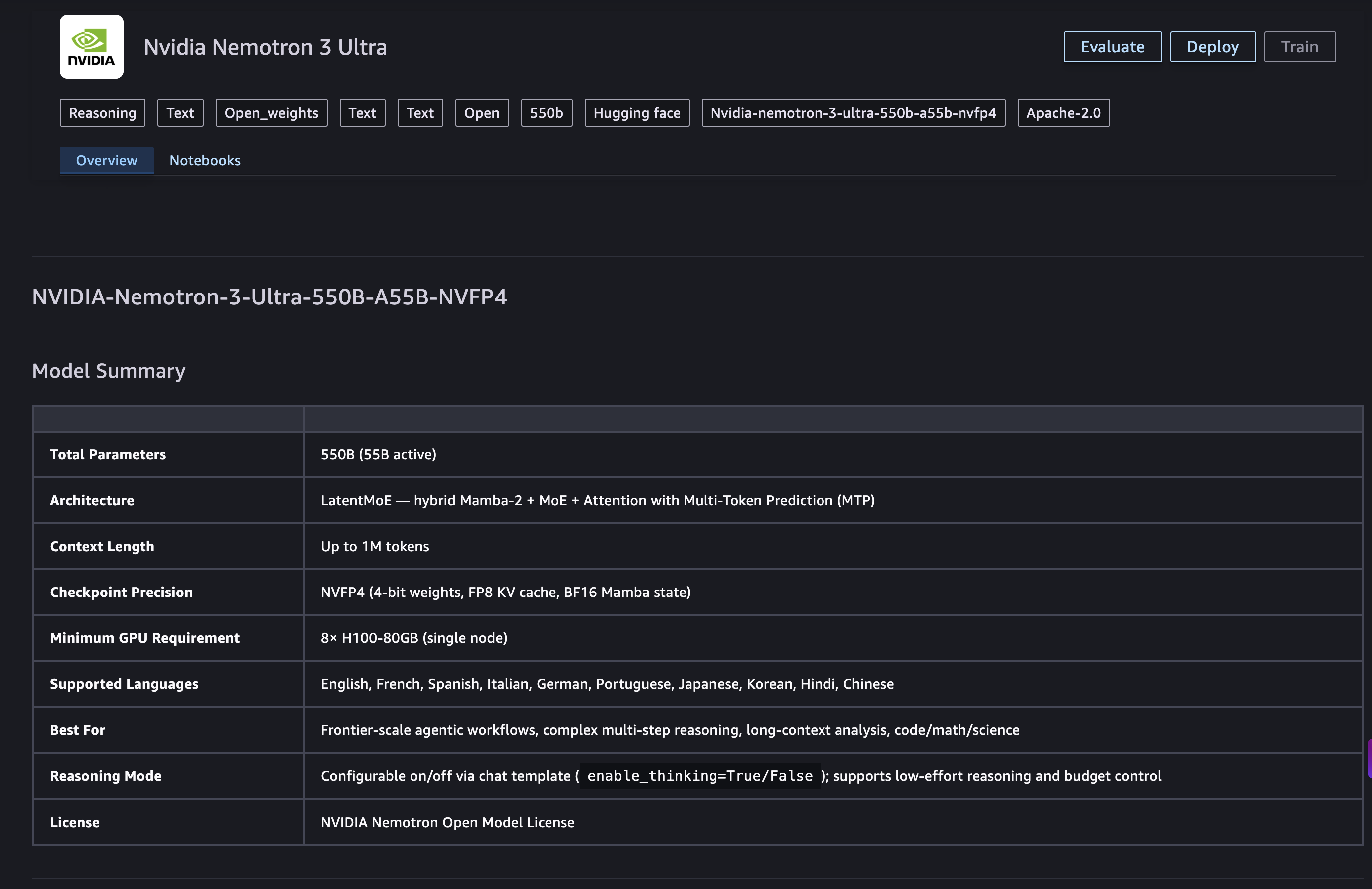
NVIDIA Nemotron 3 Ultra now available on Amazon SageMaker JumpStart
Deploy NVIDIA Nemotron 3 Ultra on Amazon SageMaker JumpStart. Get 5x faster inference and 30% lower cost for agentic AI workloads with this frontier reasoning m