DPO
Frequently Asked Questions
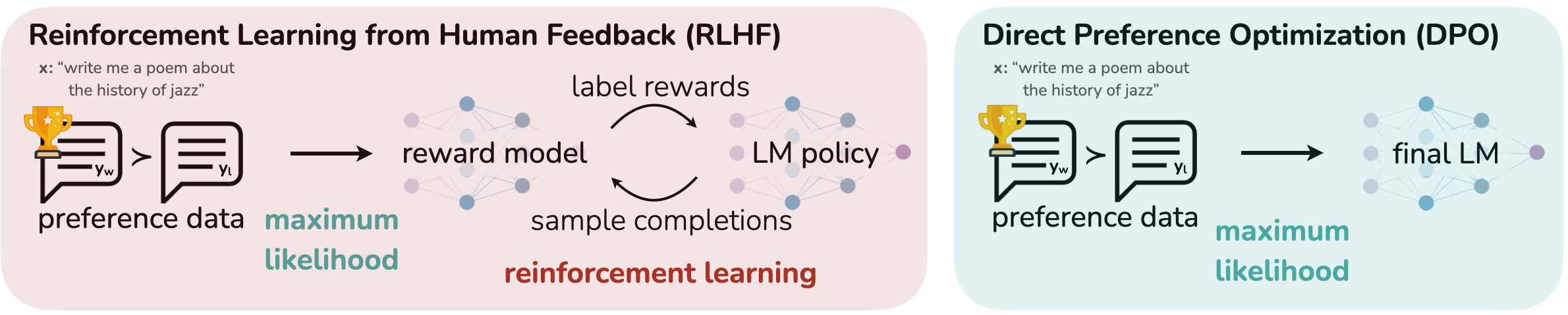
What is the main advantage of DPO over RLHF?▼
DPO is mathematically simpler, more stable, and much cheaper to run because it doesn't require training and hosting a separate reward model.
How does DPO calculate preferred behaviors?▼
It calculates the mathematical ratio of the likelihood of generating the preferred response versus the rejected response directly, pushing the model to generate the preferred one.
Quick Facts
- CategoryModel Training
- Key ApplicationSafe conversational LLM alignment, system prompt training, and response formatting
Coverage Trend12 Weeks
Related AI Terms
DPO Media Coverage & Intelligence
Monitor and debug generative AI inference with SageMaker detailed metrics and Insights dashboard on CloudWatch
Amazon SageMaker AI provides fully managed real-time inference hosting for machine learning models. You deploy a model to a SageMaker endpoint backed by one or
BlackFog launches ADX Vision for macOS to curb shadow AI leaks
BlackFog Inc. today launched ADX Vision for macOS, extending its shadow artificial intelligence detection and prevention platform to Apple Inc. endpoints so security teams can apply one data-loss policy across Windows and Mac fleets. The anti-data exfiltration company claims the release closes a gap
Optimizing Lithium Production Decisions under Geological, Demand, and Pricing Uncertainties: A POMDP Framework for Multi-Objective Decision Making
Decision making in lithium production is challenging, whether from an investor's perspective or a strategic production standpoint. Determining which mines to op

RiskIQ founders launch Ent Security with $100M to rethink endpoint defense
Intent-aware endpoint security startup Ent Security launched today with $100 million in funding to build what it calls a new layer of workspace security that reads the intent behind what users and artificial intelligence agents do before risky actions are completed. Founded by Elias Manousos and Bra
Improve your agent's tool-calling accuracy with SFT and DPO on Amazon SageMaker AI
In this post, you learn how to use Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) together to improve the tool-calling accuracy of a smal